Web Scraping for Beginners with : Python | Scrapy| BS4
Learn how to extract data from websites using : Python | Scrapy and BeautifulSoup
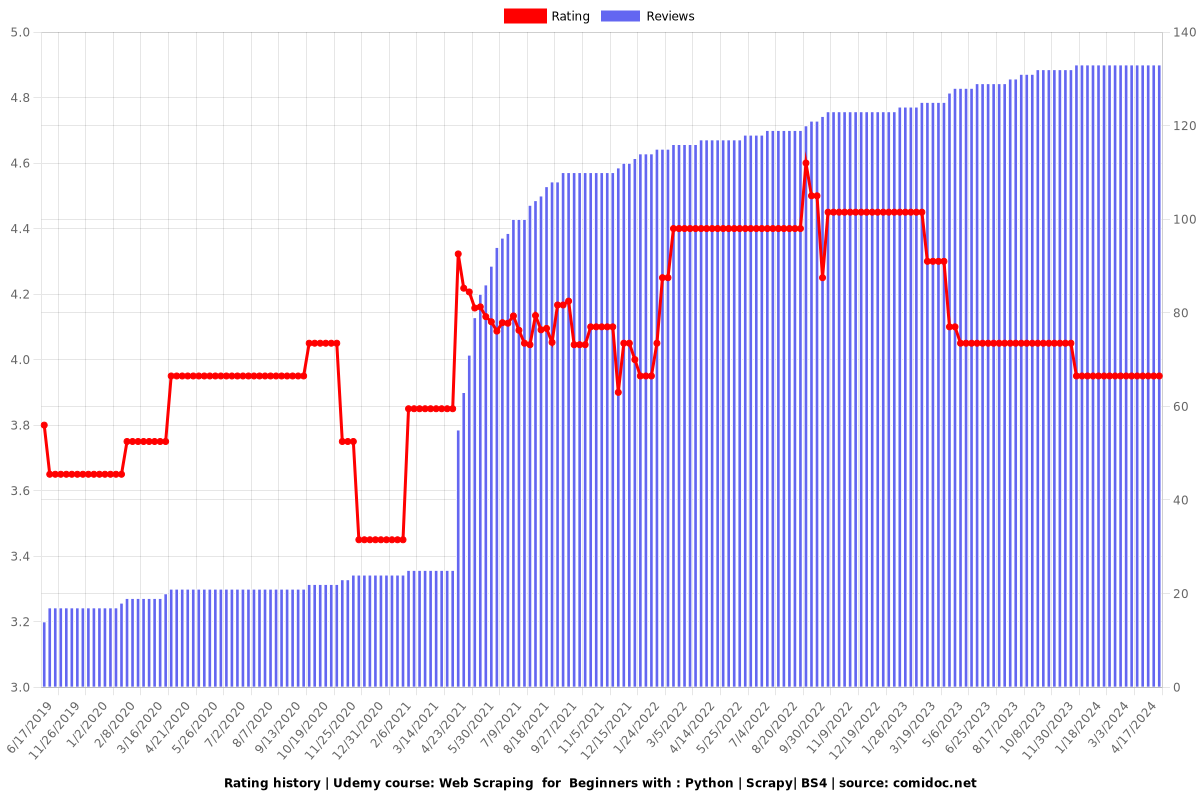
3.95 (133 reviews)

22,622
students
5 hours
content
Jun 2022
last update
$64.99
regular price
What you will learn
Install python virtual environment
Activate virtual environment
Update python and pip
Install BeautifulSoup
Install Scrapy
Inspect elements from a webpage
Prototype web scraping script with python interactive shell
Build a web scraping script with BeautifulSoup and Python
Run web scraping script
Save scraped (extracted) data to file
Create a Scrapy project
Create a Scrapy spider to crawl website and scrape data
Scrape data from a webpage using Scrapy shell
Run spider to scrape data from a website
Save output of scraped data using Scrapy to file
Why take this course?
🌐 **Unlock the Secrets of the Web with "Web Scraping for Beginners"** 🚀
Welcome to your journey into the fascinating world of web scraping! In this comprehensive course brought to you by Bluelime Learning Solutions, you'll dive headfirst into mastering Python, Scrapy, and BeautifulSoup to extract valuable data from websites. Whether you're looking to harness data for research, automate tasks, or simply satisfy your curiosity about the digital world, this course is your stepping stone to success! 🐍
### **Course Title:**
- **Web Scraping for Beginners with Python | Scrapy | BS4**
### **Course Description:**
**What is Web Scraping?** ℹ️
Web scraping is the process of automatically downloading a web page's data and extracting specific information from it. This technique allows you to gather insights, track market trends, or compile databases by extracting structured data from web sources. The extracted information can be stored in a database or as various file types for further analysis or use.
**Key Scraping Rules:** 📚
- **Legal Compliance:** Always review a website's Terms and Conditions to ensure your scraping activities comply with legal standards.
- **Respectful Usage:** Avoid aggressive requests that could overload the website's server, causing disruptions or downtime.
- **Adaptability:** Since websites evolve, make sure your code can adapt to any changes in their layout to maintain functionality.
**Tools of the Trade:** 🛠️
- **BeautifulSoup:** A python library for parsing HTML and XML documents, making it incredibly efficient at extracting data from web pages.
- **Scrapy:** An open-source framework designed for developing web crawlers and scrapers, offering robust features to handle complex tasks with ease.
**Why Learn Web Scraping?** 🤔
Web scraping software tools like Scrapy and BeautifulSoup can be used for a plethora of applications such as:
- **Data Mining:** Extracting valuable information from the web for various purposes.
- **Research:** Gathering data to analyze trends, patterns, or behavior in different fields.
- **Information Processing:** Automating the extraction and organization of data for efficient processing.
- **Historical Archiving:** Preserving web content over time for research or historical reference.
**The Web Scraping Process:** 🔁
Web scraping involves two main steps: fetching a page and extracting from it. Fetching is the process of downloading a page, which can be scheduled for later processing. Once fetched, you can then extract the data you need, whether it's parsing names and phone numbers or monitoring online price changes.
**Applications of Web Scraping:** 🌐
Web scraping is a powerful tool with applications across various domains:
- **Contact Scraping:** Collecting email addresses, phone numbers, etc., for outreach or marketing campaigns.
- **Web Indexing and Mining:** Improving web search engines by enhancing the index of available data on the internet.
- **E-commerce Price Monitoring:** Keeping track of product prices across different platforms to inform consumers about the best deals.
- **Data Analysis:** Analyzing online reviews or social media content for insights into customer sentiment or market trends.
- **Real Estate and Job Listings:** Aggregating listings from various sources for easier browsing and comparison.
- **Web Monitoring:** Tracking changes in web content to monitor compliance, updates, or breaches.
- **Online Presence and Reputation Management:** Keeping a pulse on how your brand is represented across the web.
**Web Scraping at Your Fingertips:** 🖥️
With tools provided by giants like Amazon AWS and Google, along with open-source APIs, you'll be equipped with all you need to start scraping. This course will guide you through every step of the way, from understanding the basics to applying your skills to real-world scenarios.
**Join Us on this Exciting Adventure!** 💡
Embark on a learning experience that will transform the way you interact with the web. With "Web Scraping for Beginners," you'll not only learn but also apply Python, Scrapy, and BeautifulSoup in real-world contexts. Sign up today and become a data extraction expert! 🛠️✨
---
**Enroll Now and Unlock the Digital World's Secrets with Web Scraping!** 🌟 Your data journey begins here.
Our review
🌟 **Overall Course Rating:** 3.95/5
## Pros:
- **Engaging Presentation Style:** The course features nice graphics and concise modules, which make it a refreshing change from other Udemy courses. (Reviewer 1)
- **Efficient Video Length:** Each video module is short and sweet, typically running under 10 minutes, allowing for quick learning sessions without the presenter rambling on. (Reviewer 2)
- **Good Starting Point:** It serves as a good introduction to Scrapy for those who are already familiar with Python, Request, and BeautifulSoup. (Reviewer 2)
- **Clear and Structured Content:** Most of the content is presented quite clearly, and for beginners, it starts with the basics, which is helpful. (Reviewer 5)
- **Comprehensive Coverage:** The course offers a very complete introduction to web scraping if you meet the basic requirements. (Reviewer 9)
- **Practical Approach:** It's a good course for beginners, despite some drawbacks, and it provides a practical approach to learning web scraping. (Reviewer 10)
## Cons:
- **Outdated Content:** The course is out of date by approximately two years, with references to now-obsolete software like Atom and potentially outdated Amazon web page structures. (Reviewer 11)
- **Code Debugging Issues:** Some code examples provided in the course may not work due to changes over time, leading to frustration and additional research outside of the course. (Reviewer 11)
- **Repetitive Material:** There is significant repetition of concepts within the lessons, such as lesson 4's concepts being reiterated in lesson 5. (Reviewer 2)
- **HTML and CSS Overemphasis:** There is an excessive discussion about HTML, which is not relevant for beginners, and an early introduction to CSS that could be omitted in a beginning scraping course. (Reviewer 2)
- **Question Response Inefficiency:** The content was not organized well, and there were instances where questions asked by learners were not addressed. (Reviewer 8)
- **Inadequate Code Documentation:** The code used in the scripts should be available as a reference, and the course should promote good programming style with commented lines. (Reviewer 2)
- **Software Installation Challenges:** The software setup part is very outdated, and the code provided for setting up software and packages did not work without additional research. (Reviewer 6)
- **Lack of Advanced Content:** For those looking to learn more advanced aspects of scraping and crawling, the course may fall short, as it spends too much time on basic concepts. (Reviewer 7 & Reviewer 10)
## Additional Observations:
- **Course Structure:** Some lessons could be streamlined by wrapping functionality in small functions for easier testing and error catching, such as the spelling error pointed out in lesson 21. (Reviewer 3)
- **Pedagogical Approach:** The course could benefit from a more structured approach to teaching Scrapy, with a clear progression from basic to advanced concepts. (Reviewer 2 & Reviewer 7)
- **Udemy Platform Recommendation:** The course is recommended by users who find it fits well within their current learning path, particularly those who trust Bluelime's instructional quality. (Reviewer 8 & Reviewer 10)
## Final Verdict:
The course offers a solid foundation in web scraping for beginners and is comprehensive if you are already familiar with the basics of Python and web automation tools. However, it requires an update to align with current technologies and practices, and it may not be suitable for those who need more advanced Scrapy instruction. Overall, despite some significant drawbacks, it remains a useful resource for starting out in web scraping.
Charts
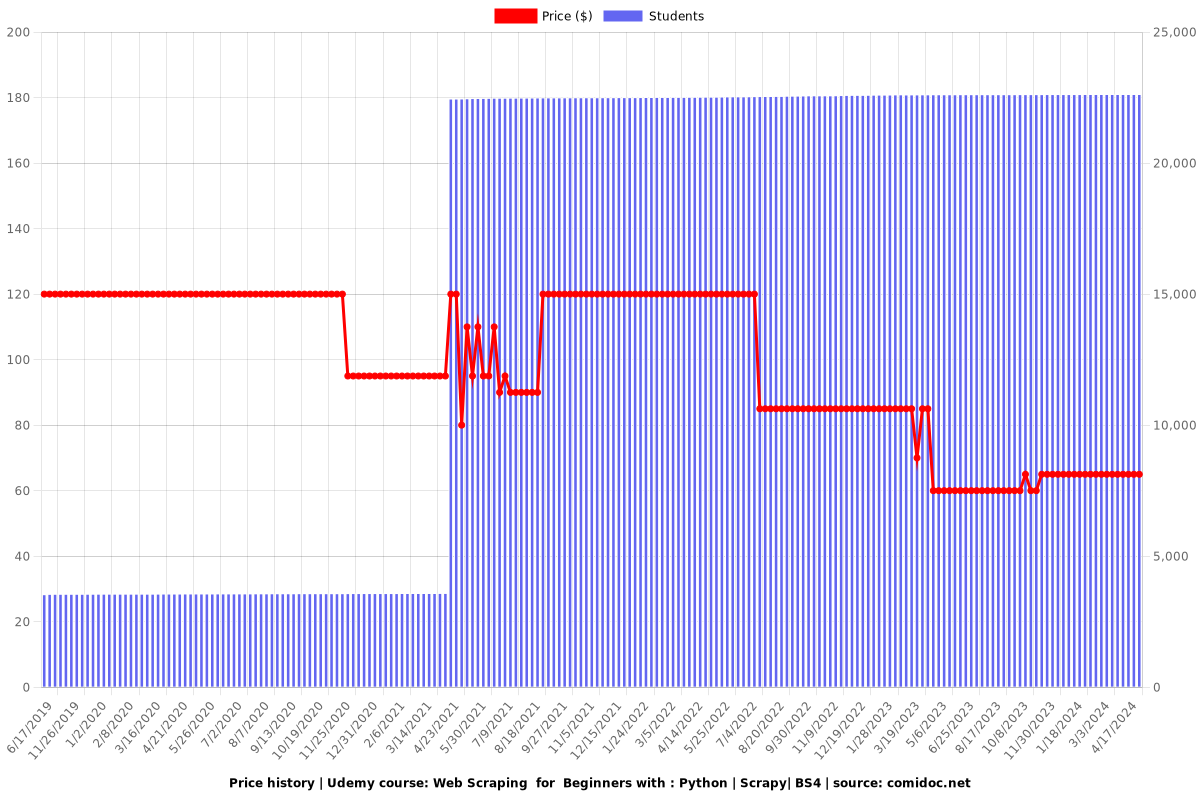
Price
Rating
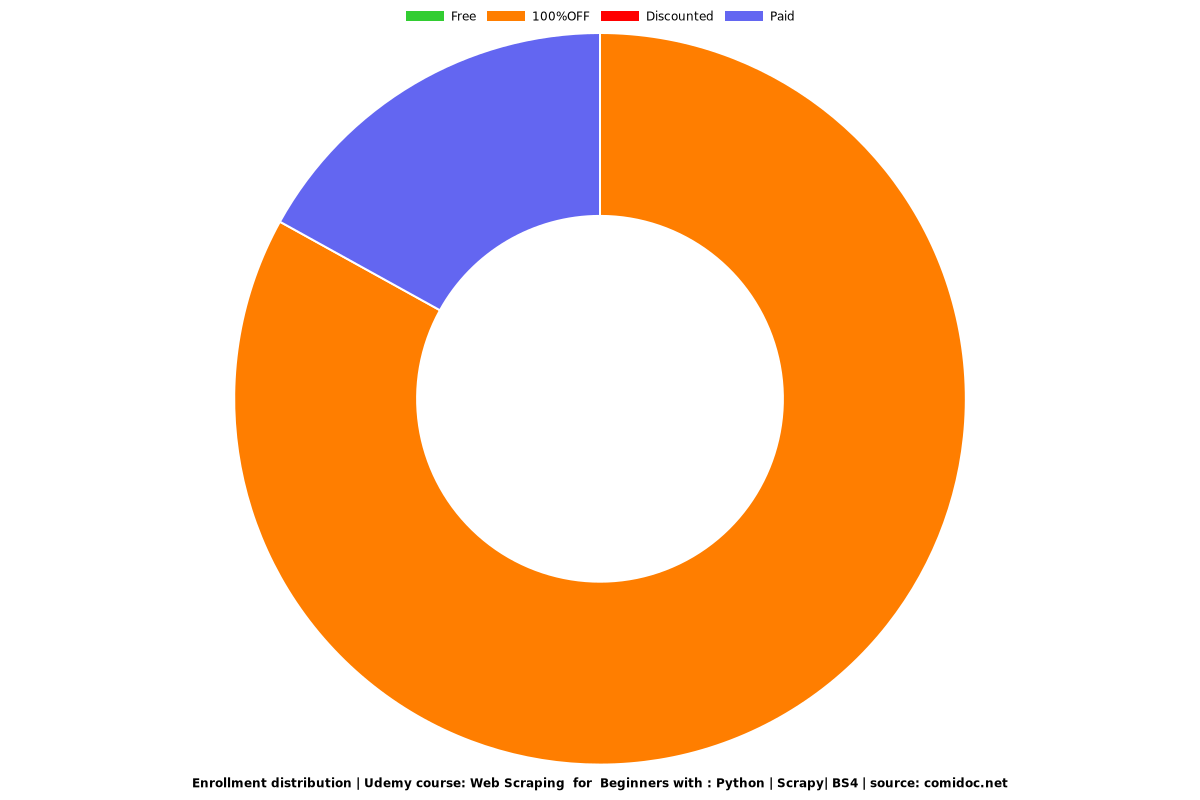
Enrollment distribution
Related Topics
2173984
udemy ID
1/24/2019
course created date
6/17/2019
course indexed date
Bot
course submited by