Spark y Scala en Databricks: Big Data e ingeniería de datos
Trabajo desde niveles básicos hasta avanzados con RDD y DataFrame.

What you will learn
Conocer el funcionamiento y la estructura de Apache Spark
Trabajar con RDDs de Spark desde niveles básicos hasta avanzados
Trabajar con DataFrames en Spark mediante el API de SQL desde niveles básicos hasta avanzados
Optimizar sus aplicaciones de Apache Spark para el manejo de grandes volúmenes de datos a través de DataFrames
Why take this course?
Bienvenidos al curso Spark y Scala en Databricks: Big Data e ingeniería de datos.
En este curso aprenderás a trabajar con Scala-Spark en Databricks.
Spark es esencialmente un sistema distribuido que fue diseñado para procesar un gran volumen de datos de manera eficiente y rápida. El objetivo de este curso es aprender a trabajar con las principales abstracciones de Spark, las cuales son los RDDs y los DataFrames.
El material que proponemos en el curso está pensado para todas las personas que bien deseen iniciarse en el trabajo con Spark, o que por otro lado, deseen consolidar los conocimientos que ya poseen sobre los temas que se abordarán. El curso está diseñado de una forma progresiva y gradual que le permitirá al estudiante entender y desarrollar las principales habilidades para el trabajo con RDDs y DataFrames en Spark. Además, se abordarán temas avanzados que le permitirán optimizar las aplicaciones de Spark que pueda construir en un futuro, o bien, mejorar aquellas que ya se tengan implementadas.
Empezamos el curso con una breve introducción al Big Data y a Spark. Posteriormente continuamos con una sección dedicada a explicar los aspectos fundamentales de Databricks Community Edition que necesitaremos para el desarrollo del curso. Una vez hayan concluido esta sección, estarán en condiciones de ejecutar notebooks de Scala-Spark en Databricks. Las siguientes secciones del curso están pensadas para entender y aplicar en la práctica las principales cuestiones sobre los RDDs y los DataFrames.
El temario procura en todo momento analizar temas específicos por cada lección, permitiéndole así al estudiante localizar rápidamente cualquier contenido de una forma rápida. La mayoría de las lecciones están conformadas por una parte teórica y otra práctica.
Mi nombre es José Miguel Moya y me desempeño actualmente como Ingeniero de Datos. Como parte de mi trabajo diario utilizo Spark con Python y Scala para obtener y procesar enormes cantidades de datos.
Te invito a que veas el video de presentación del curso y las lecciones gratuitas.
Te espero en el curso, tenga usted un cordial saludo.
Screenshots




Reviews
Charts
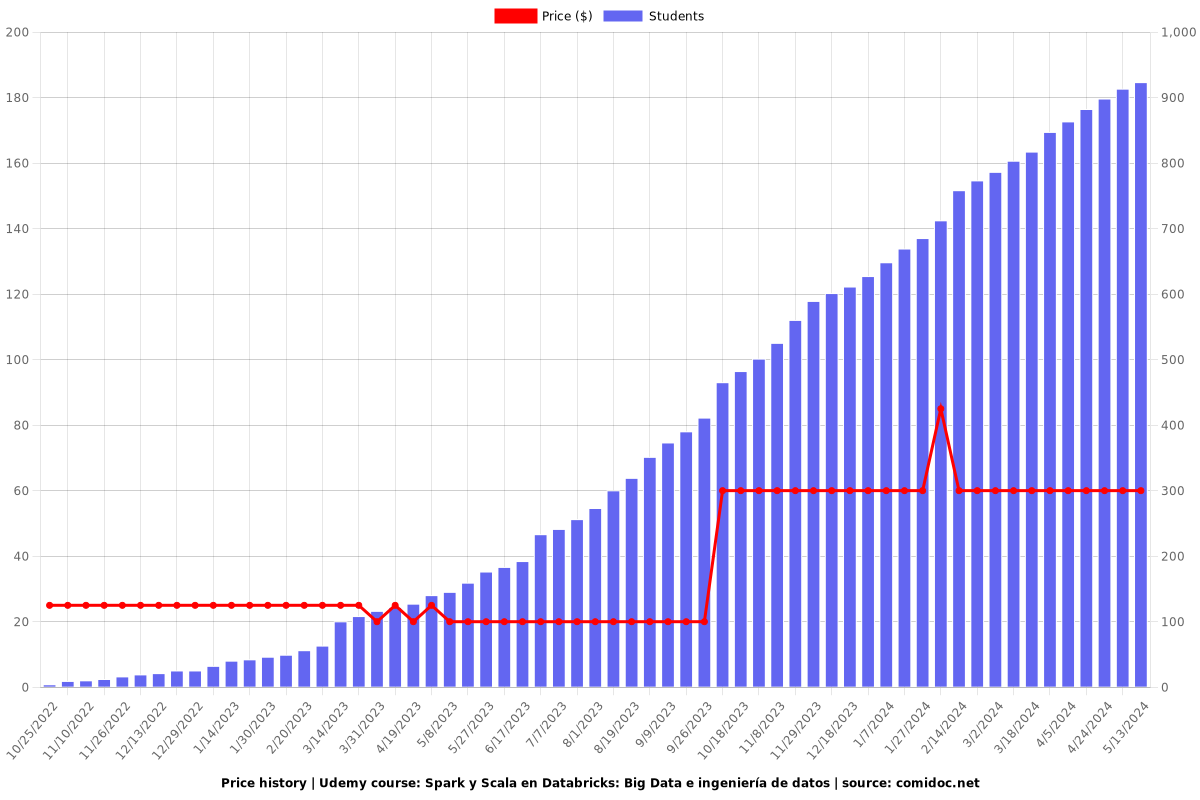
Price
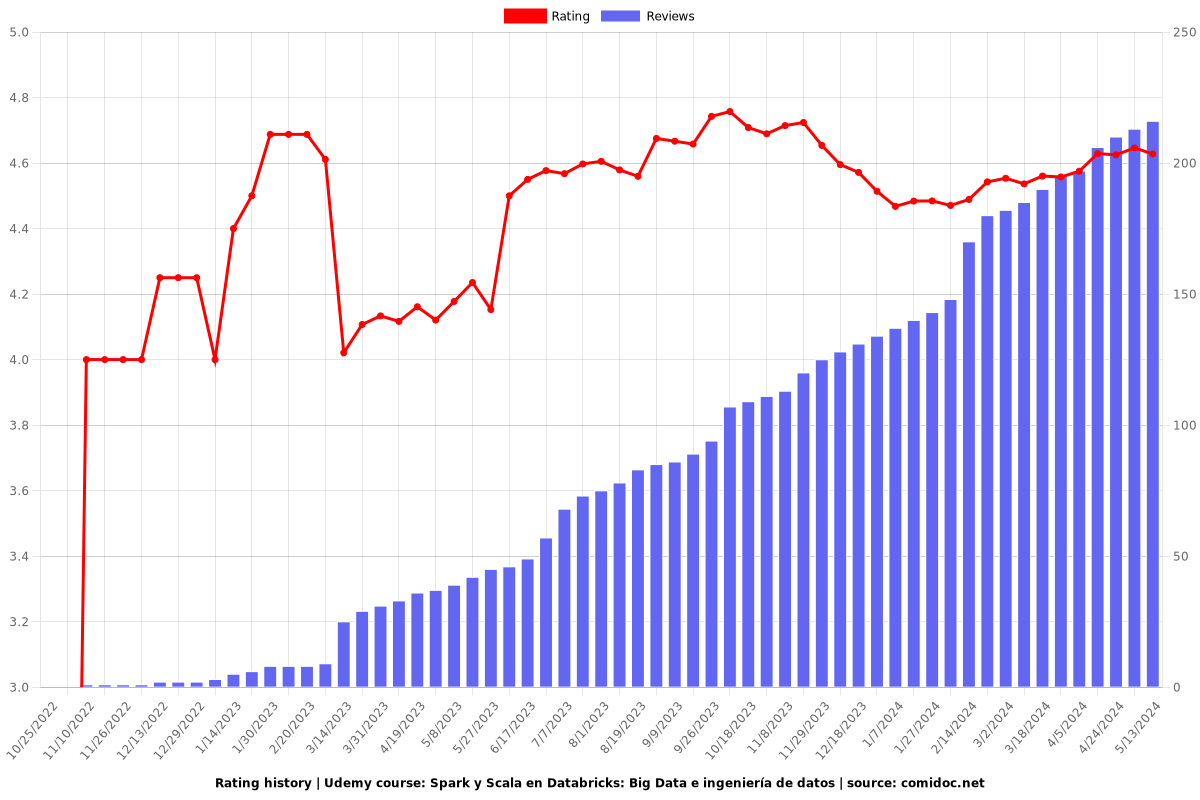
Rating
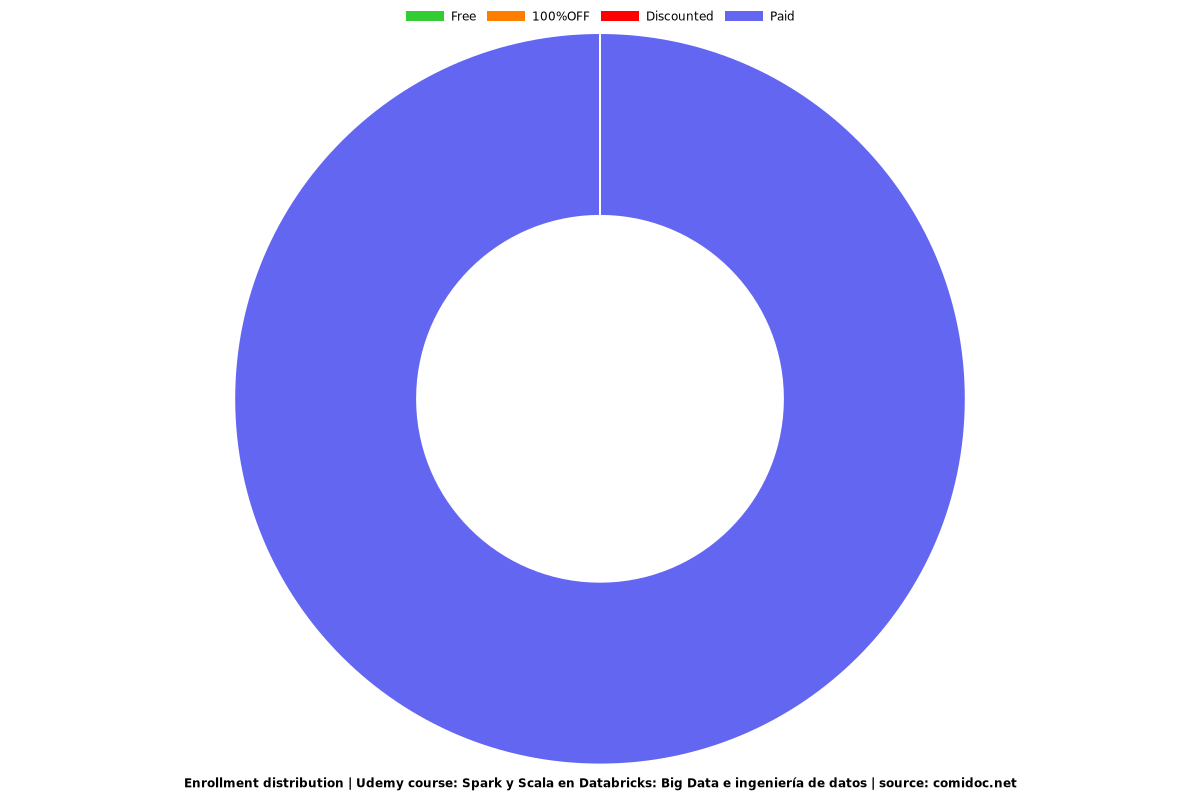
Enrollment distribution