Title
Mastering and Tuning Decision Trees
IBM SPSS Modeler Seminar Series

What you will learn
Understand the theory behind classification trees
Differentiate between classification tree algorithms
Know the assumptions of classification trees
Learn the advantage and disadvantages of the different algorithms
Interpret the results
Why take this course?
🎓 Course Title: IBM SPSS Modeler Seminar Series: Mastering and Tuning Decision Trees 🌳
Headline: Dive into the World of Advanced Analytics with IBM SPSS Modeler! 🚀
Course Description:
Are you ready to unlock the full potential of your data and master the art of predictive modeling? Look no further! Our comprehensive online course, "Mastering and Tuning Decision Trees", is tailored for analysts who want to harness the power of IBM SPSS Modeler without delving into complex programming. 🛠️
Why Take This Course?
- Easy-to-Use Interface: Discover how IBM SPSS Modeler simplifies predictive analytics, making it accessible to analysts and decision-makers at all levels.
- Hands-On Learning: Engage with a series of self-paced videos designed to take you from novice to proficient in using Decision Trees for data analysis.
- Versatile Techniques: Explore the key decision tree methods – CHAID, C5.0, CRT, and QUEST – and understand their applications and differences.
What You Will Learn:
- Concepts and Applications: Gain a solid foundation in when and how to use Decision Trees for data analysis, including the assumptions that underpin this methodology.
- Automated & Interactive Analysis: Learn to conduct automated analyses with ease and delve into interactive explorations for more nuanced insights.
- Results Interpretation: Develop the skills to interpret decision tree results effectively, ensuring your findings are actionable and meaningful.
In-Depth Focus:
- CHAID vs. C&RT: A detailed comparison of two powerful Decision Tree methods, highlighting their strengths and ideal use cases.
- Tuning for Optimal Performance: Master the art of fine-tuning your models using both CHAID and C&RT to achieve the best possible results. 🔨
Course Structure:
- Introduction to IBM SPSS Modeler: A brief overview of the platform's capabilities and how it can transform your data analysis workflow.
- Decision Tree Methods: A deep dive into CHAID, C5.0, CRT, and QUEST, with real-world examples for each method.
- Modeling Best Practices: Techniques for effective model building, from selecting the right variables to interpreting results correctly.
- Advanced Tuning Strategies: Step-by-step guidance on how to adjust parameters in CHAID and C&RT to optimize your model's performance.
- Real-Time Application: Learn how to deploy your models to make real-time predictions based on new data, keeping your analysis up-to-date and relevant.
Who Is This Course For?
- Data Analysts seeking to expand their skill set with predictive modeling techniques.
- Business Professionals who want to leverage analytics for strategic decision-making.
- Aspiring Data Scientists looking to build a robust portfolio of analytical skills.
By the end of this course, you'll be equipped with the knowledge and tools necessary to make informed decisions and drive data-driven insights within your organization. 💼
Enroll now to start your journey towards mastering Decision Trees in IBM SPSS Modeler! Your path to becoming a data analysis expert begins here. Let's turn your data into valuable predictions together! 🎉
Screenshots




Reviews
Charts
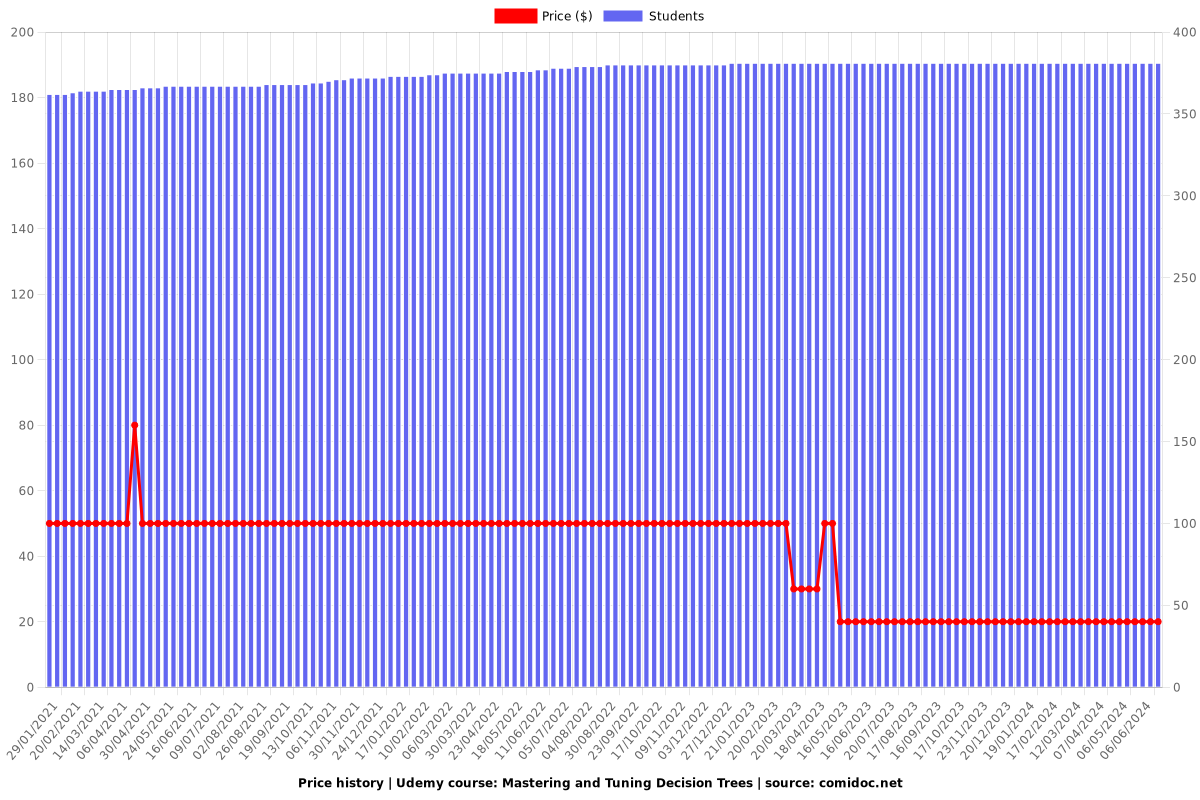
Price
Rating

Enrollment distribution