Databricks e APACHE HOP: dados e seus tratamentos
Trabalhe com o ecossistema Databricks e entenda de integração de dados com o APACHE HOP

What you will learn
Visualização para explorar resultados de consultas de diferentes perspectivas
Construção de gráficos e Dashboards
Unificação de dados em diversos formatos: texto, JSON, PARQUET, dentre outros
Trabalhada por administrador da plataforma, analista de dados, cientista de dados e engenheiro de dados com diversas funcionalidades
Aprendizado processamento distribuído em SPARK
Entendo o que é Databricks File System (DBFS) seu sistema de arquivos
Entendo sobre Cluster
Aprendendo a gerenciar e criar Notebooks em R, SCALA, Python e SQL
Executando scripts multilinguagens
Gerenciando a ingestão de dados e análise de dados, gerando gráficos e dashboards
Construindo na versão community
Trabalhando com a biblioteca dbutils Python
Integrando o Databricks ao Power BI
O que é Hop Orchestration Platform
Entendendo sobre fluxos de trabalho e pipelines
Entendendo sobre projetos e ambientes
Instalação do APACHE HOP
Criando pipelines com arquivos texto
Realizando tratamento de dados para entendimento do processo de engenharia de dados
O que são transformações, links e ações dentro de um pipeline
Construindo um workflow, orquestrador da sequência das operações
Entendendo o HOP GUI e seus componentes
Entendendo menu barras, principal e perspectivas
Criando sua área de projetos
Componentes pipelines: Sort, Select value, CSV file input, Value mapper, Filter rows, Dummy, Unique rows, Merge Join, Text File Output
Entendendo o que é : View output, Preview output , Debug output
Componentes pipelines: Number Range, Concat Field, String Operations, Replace in String, IF Field Value is Null, Split Fields, CSV File Input, Mail, File Exist
Leitura de dados em uma API: Rest Client, JSON Input, JSON Output
Construindo Workflow com execução de pipelines
Entendo o uso de variáveis globais no APACHE HOP
Automatização de pipeline ou workflow pelo HOP-RUN
Construindo pipelines em banco de dados Postgresql: Table Input, Table Output, Configurando conexão
Instalação de banco de dados Postgresql, usando PGAdmin
Why take this course?
Criamos um dos treinamentos mais interessante do mercado, que liga a atuação do analista de dados, engenheiro de dados e de todos os profissionais que manipulam, tratam e utilizam dados no seu dia dia em duas das principais ferramentas do mercado, conheçam o Databricks e o APACHE HOP.
Inicialmente iremos aprender como trabalhar com dados no produto Databricks, que permite que você trabalhe com conceitos dos mais utilizados no mercado: SPARK, NÓ, CLUSTER. Aqui será possível utilizar o conceito de multilinguagem dentro da construção de seus projetos de dados utilizando o conceito de notebooks. Você poderá ter em um mesmo notebook: SCALA, R, PYTHON e SQL. Entenderá o poder de trabalhar com o SPARK e suas aplicações, além de entender todo o propósito do uso do Databricks.
Em seguida você entrará no mundo do pipeline e workflow com a ferramenta APACHE HOP, de última geração, totalmente visual, você irá construir projetos que tratam e manipulam dados, é um produto que tem mais de 400 plugins ou componentes, tudo muito simples e fácil, basta arrastar o componente e realizar uma tarefa: união de dados, troca de valores, ajustes e retiradas de informações inconsistentes, gravação de dados em arquivos TXT, CSV, XLS e em banco de dados e muitas outras ações.
Então venha e aprenda a trabalhar com estas duas ferramentas incríveis que todo engenheiro de dados, analista de dados ou profissional de dados em geral está utilizando.
Entre para este clube que não para de crescer!
Screenshots




Charts
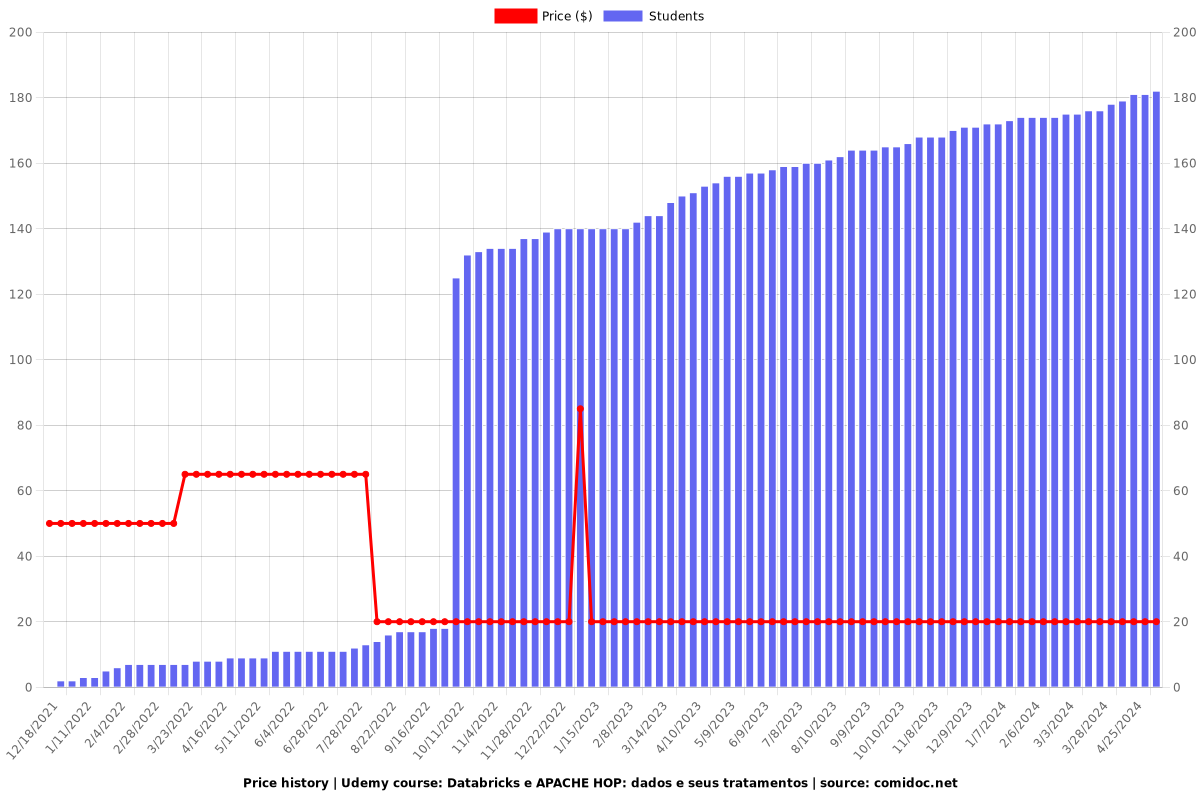
Price
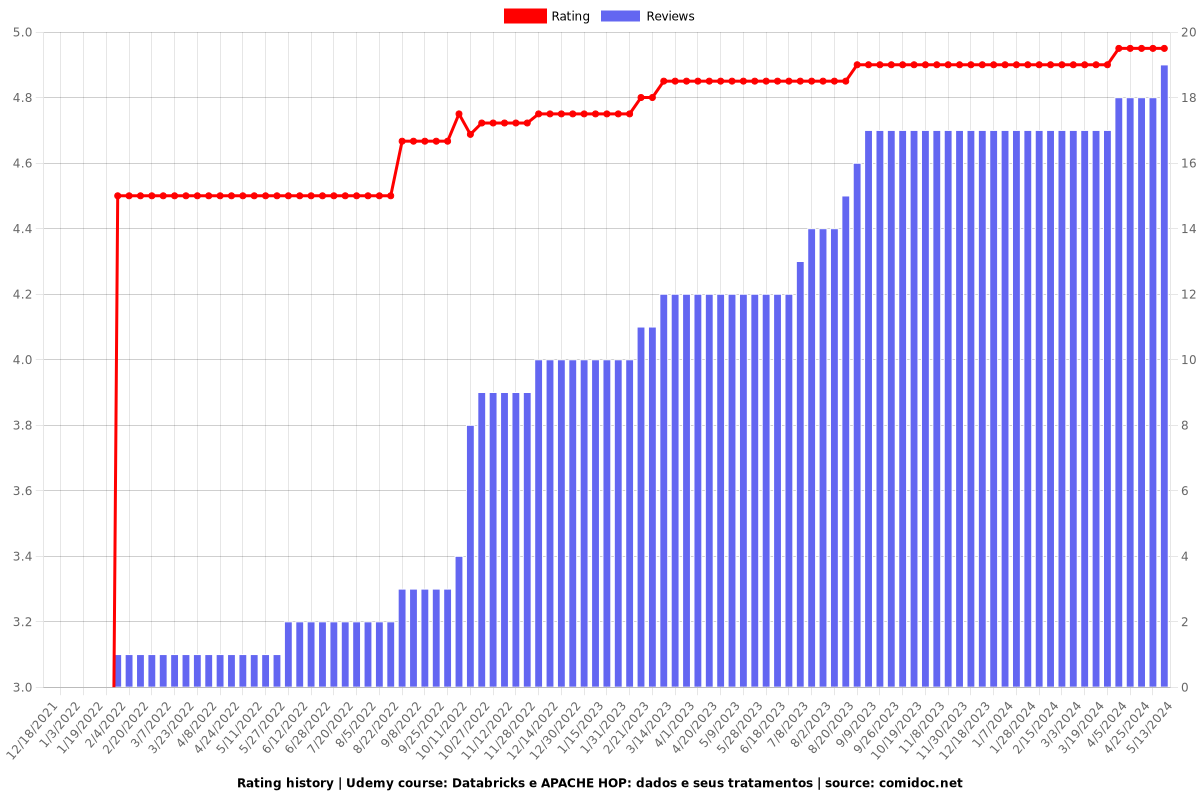
Rating
Enrollment distribution