Big Data Projects 2024
Work with Big Data Tools, SQL Databases, AWS, ETL, Data Integration Tools & more to master real-world Big Data Projects

What you will learn
How to Build a Scalable Data Pipeline using various Components
Data Warehouse Design
Data Preparation,Cleaning, Data Transformation and Manipulation
Industry Project Ready projects
Why take this course?
The Big Data Projects course is designed to provide students with an in-depth understanding of the various tools and techniques used to handle and analyze large-scale data. The course will cover topics such as data preprocessing, data visualization, and statistical analysis, as well as machine learning and deep learning techniques for data analysis.
Throughout the course, students will be introduced to the Hadoop ecosystem, including technologies such as Hadoop Distributed File System (HDFS), MapReduce, and Apache Spark. Students will also gain hands-on experience working with big data tools such as Apache Hive, Pig, and Impala.
At the end of the course, students will have the necessary skills and knowledge to handle large-scale data and analyze it effectively. Students will also have a solid understanding of the Hadoop ecosystem and various big data tools that are commonly used in the industry.
A real data engineering project usually involves multiple components. Setting up a data engineering project, while conforming to best practices can be extremely time-consuming. If you are
A data analyst, student, scientist, or engineer looking to gain data engineering experience, but are unable to find a good starter project.
1. Wanting to work on a data engineering project that simulates a real-life project.
2. Looking for an end-to-end data engineering project.
3. Looking for a good project to get data engineering experience for job interviews.
Then this Course is for you. In this Course, you will
Learn How to Set up data infrastructure such as Airflow, Redshift, Snowflake, etc
Learn data pipeline best practices.
Learn how to spot failure points in data pipelines and build systems resistant to failures.
Learn how to design and build a data pipeline from business requirements.
Learn How to Build End to End ETL Pipeline
Set up Apache Airflow, AWS EMR, AWS Redshift, AWS Spectrum, and AWS S3.
Tech stack:
➔Language: Python
➔Package: PySpark
➔Services: Docker, Kafka, Amazon Redshift,S3, IICS, DBT Many More
Requirements
This course presume that students have prior knowledge of AWS or its Big Data services.
Having a fair understanding of Python and SQL would help but it is not mandatory.
Every Month New Projects will be added
Charts
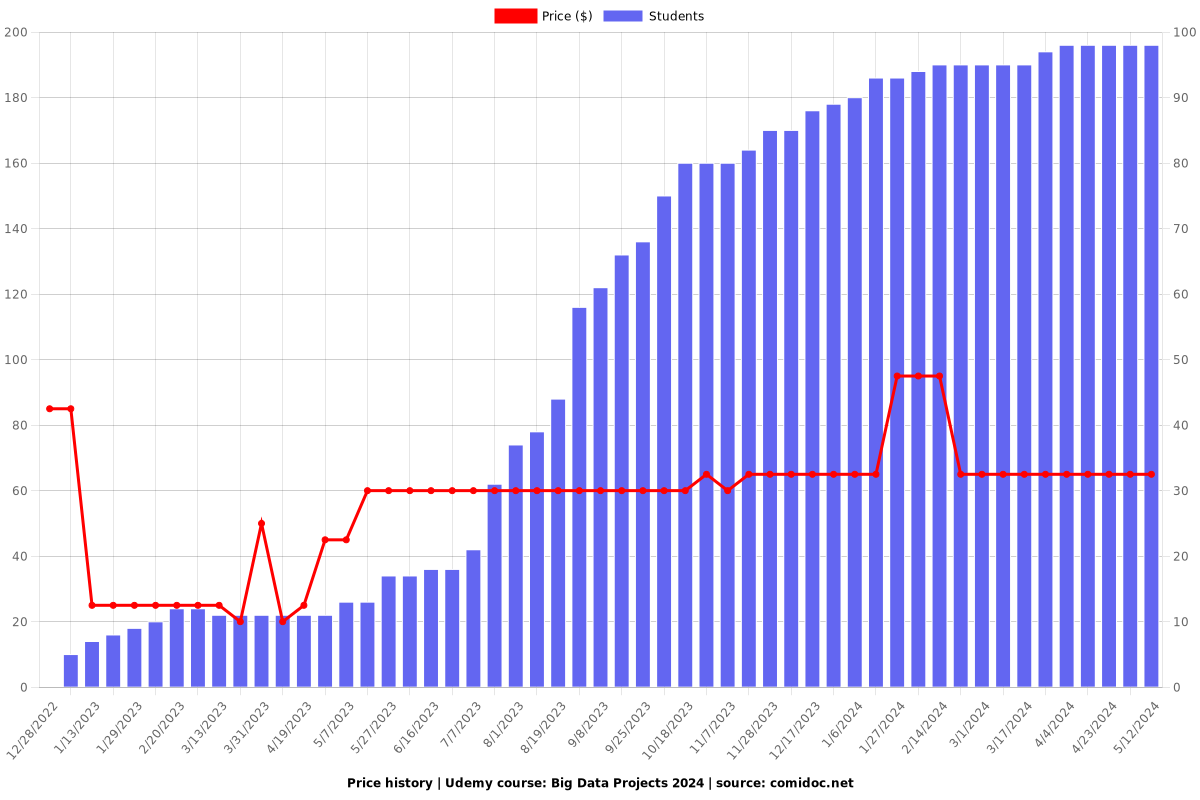
Price
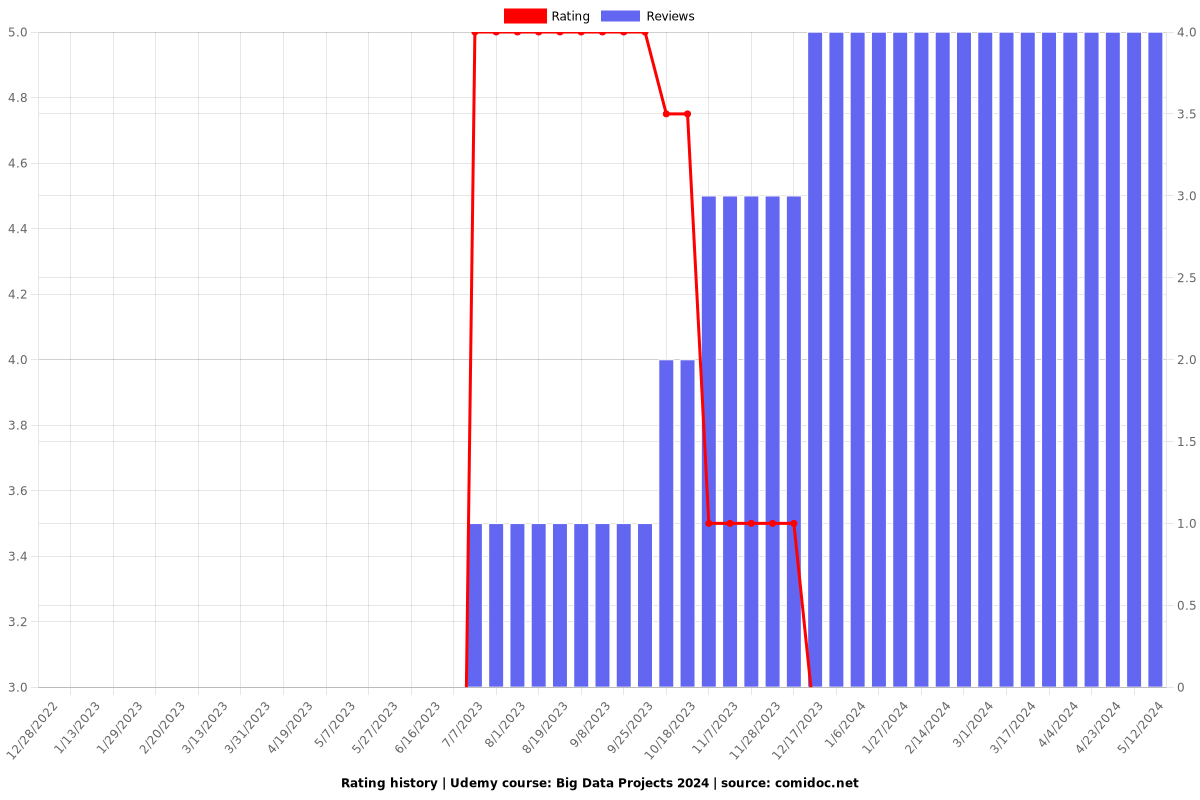
Rating
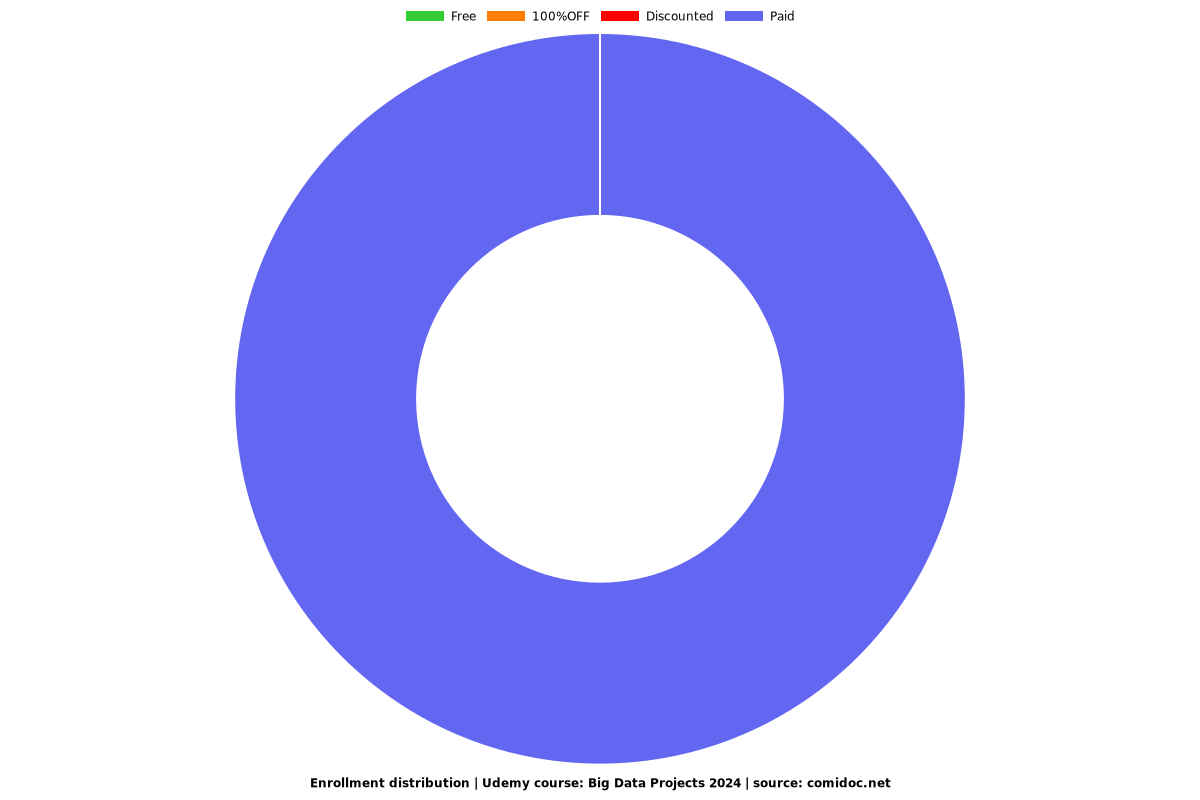
Enrollment distribution