【한글자막】 Apache Spark 와 Scala로 빅 데이터 다루기
【전세계 81만 수강 TOP강사!】 Desktop 또는 Scala가 포함된 Hadoop에서 대규모 데이터 세트를 분석하는 20개 이상의 실습 예제가 포함된 Apache Spark 튜토리얼!

What you will learn
빅데이터 분석 문제를 Apache Spark 스크립트로 프레임화
Scala 프로그래밍 언어를 사용하여 분산 코드 개발
파티셔닝, 캐싱 및 기타 기술을 통해 Spark 작업 최적화
Hadoop 클러스터에서 Spark 스크립트 구축, 디플로이 및 실행
Spark Streaming으로 연속적인 데이터 스트림 처리
SparkSQL, DataSets 및 DataFrames를 사용하여 구조화된 데이터 변환
GraphX를 사용하여 그래프 구조 순회 및 분석
Spark의 머신 러닝으로 방대한 데이터 세트 분석
Why take this course?
Spark와 Scala를 함께 배우는 강의!
20개 이상의 실제 예시 포함!
Spark의 기초부터 시작하여 다양한 응용까지 All in one!
스칼라 단기 집중 강의 포함!
Amazon 및 IMDb의 전 엔지니어이자 선임 관리자로부터 배우는 실습 위주 수업!
*프로그래밍을 처음 접한다면 수업을 진행하기 어려울 수 있습니다. 프로그래밍 기초 강의를 먼저 수강하시는 것을 추천합니다*
Apache Spark 와 Scala로 빅 데이터 다루기 강의를 선택해야 하는 이유
데이터 분석 문제를 Spark로 프레이밍 하는 기술을 배우고, 20개 이상의 실습 예제를 통해서 완벽히 마스터 할 수 있습니다.
수강 후에는 몇 분만에 클라우드에서 GB 크기의 정보를 분석하는 코드를 실행할 수 있게 됩니다.
Spark는 Scala 프로그래밍 언어를 사용할 때 가장 잘 작동하며, 이 강의는 스칼라 단기 집중 강의를 포함하므로 빠르게 배울 수 있습니다.
(만약 Python에 더 익숙한 사용자라면 다른 강의를 추천 드립니다)
이 강의에는 재미있는 실습이 포함 되어 있습니다. Spark를 사용하여 영화 등급 데이터와 책의 텍스트를 분석하는 몇 가지 간단한 예로 시작해서 기본기를 배운 후에는, 더 복잡하고 흥미로운 작업을 진행합니다. 백만개의 영화 등급을 사용하여 서로 유사한 영화를 찾을 것이고, 이 과정에서 여러분들이 좋아할 만한 새로운 영화를 발견할 수도 있을 것입니다! 여러분은 슈퍼히어로의 사회적 그래프를 분석하고 가장 "인기 있는" 슈퍼히어로가 누구인지 배우고 슈퍼히어로 사이의 "Degree of Separation"를 찾는 시스템을 개발할 것입니다. 모든 마블 슈퍼히어로들은 스파이더맨과 얼마나 연결되어 있을까요?
이 강의를 통해 그 답을 찾을 수 있습니다.
또한, 이 강의는 실습 위주의 강의입니다. Amazon의 Elastic MapReduce 서비스를 사용하여 자체 시스템과 클라우드 모두에서 실제 코드를 함께 작성, 분석 및 실행할 때 강사와 함께 대부분의 시간을 보내게 됩니다. 7시간 분량의 영상 내용이 포함되어 있으며, 20개 이상의 실제 예시는 복잡성이 증가함에 따라 스스로 구축하고 실행하고 연구할 수 있습니다.
Apache Spark 와 Scala로 빅 데이터 다루기 세부 커리큘럼
빅데이터 분석 문제를 Apache Spark 스크립트로 프레임화
Scala 프로그래밍 언어를 사용하여 분산 코드 개발
파티셔닝, 캐싱 및 기타 기술을 통해 Spark 작업 최적화
Hadoop 클러스터에서 Spark 스크립트 구축, 디플로이 및 실행
Spark Streaming으로 연속적인 데이터 스트림 처리
SparkSQL, DataSets 및 DataFrames를 사용하여 구조화된 데이터 변환
GraphX를 사용하여 그래프 구조 순회 및 분석
Spark의 머신 러닝으로 방대한 데이터 세트 분석
Amazon 및 IMDb의 전 엔지니어이자 선임 관리자 Frank Kane 강사의 한마디!
완전히 업데이트 된 새로운 강의로 출시되었습니다!
Spark 3, IntelliJ, 구조적 스트리밍 및 DataSet API에 대한 더 강력한 초점을 위해 완전히 업데이트되어 다시 녹음되었습니다.
Spark SQL, Spark Streaming과 같은 최신 Spark 기술과 Gradient Boosted Trees와 같은 고급 모델도 다룰 것입니다.
"빅 데이터" 분석은 아주 인기있고 매우 가치 있는 기술입니다. 이 강의는 빅 데이터에서 가장 인기 있는 기술을 알려줍니다. 바로 Apache Spark 입니다. 아마존, 이베이, NASA JPL 및 Yahoo를 포함한 고용주는 모두 Spark를 사용하여 내결함성 Hadoop 클러스터 전반에 걸쳐 방대한 데이터 세트에서 의미를 빠르게 추출합니다. 집에서 자신의 Windows 시스템을 사용하여 동일한 기술을 배우게 될 텐데, 생각하는 것보다 쉬울 것이며 Amazon 및 IMDb의 전 엔지니어이자 수석 관리자에게 배우게 될 것입니다.
여러분의 일정에 따라 여러분의 속도로 진행하세요. 이 강의는 Spark SQL, Spark Streaming, GraphX를 비롯한 다른 Spark 기반 기술에 대한 개요로 마무리됩니다.
강의를 들으시고 강의와 관련하여 궁금하신 점은 무엇이든 Q&A에 남기실 수 있지만, 꼭 영어로 남겨주세요. 그래야 답변을 드릴 수 있습니다. :)
지금 등록하고 이 강의를 즐겨보세요!
-Frank
P.S. 제 강의에 대한 한 수강생의 리뷰 하나를 소개해 드립니다:
"나는 Frank의 "Apache Spark 2 with Scala - Hands On with Big Data!" 강의를 통해 처음으로 Spark를 공부했습니다. Scala에 대한 지식과 가장 중요한 Spark 응용 프로그램의 실제 사례를 얻는 것은 저에게 훌륭한 출발점이 되었습니다. 모든 관련 Spark 핵심 개념, RDD, 데이터 프레임 및 데이터 세트, Spark Streaming, AWS EMR에 대한 이해를 주었습니다. 완강 후 몇 개월 만에, 저는 이 강의에서 얻은 지식을 사용하여 현재 회사에서 주로 Spark 응용 프로그램 작업을 제안했습니다. 그 이후로 나는 계속해서 Spark로 작업했습니다. Frank는 개념을 잘 단순화하고 강의 방식은 따라하고 계속하기 쉽기 때문에 나는 Frank 강의를 강력히 추천합니다! " - 조이 파허티
Screenshots




Charts
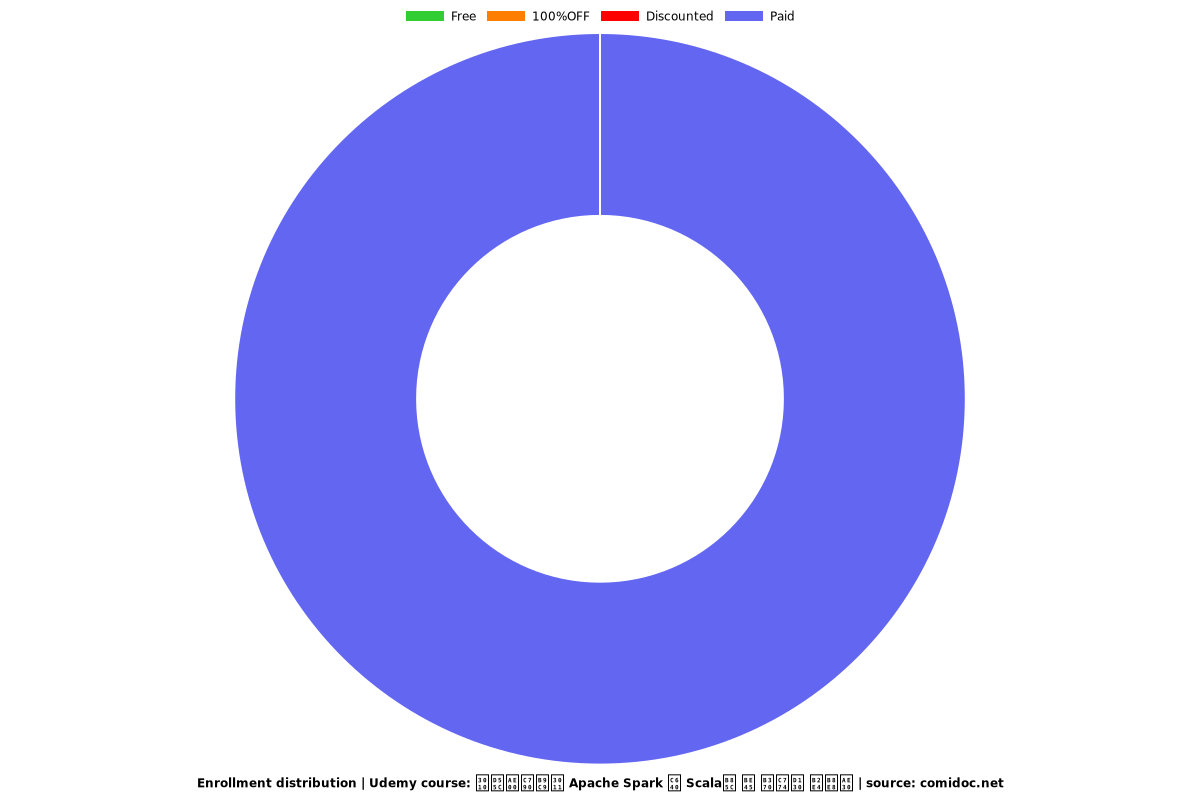
Price
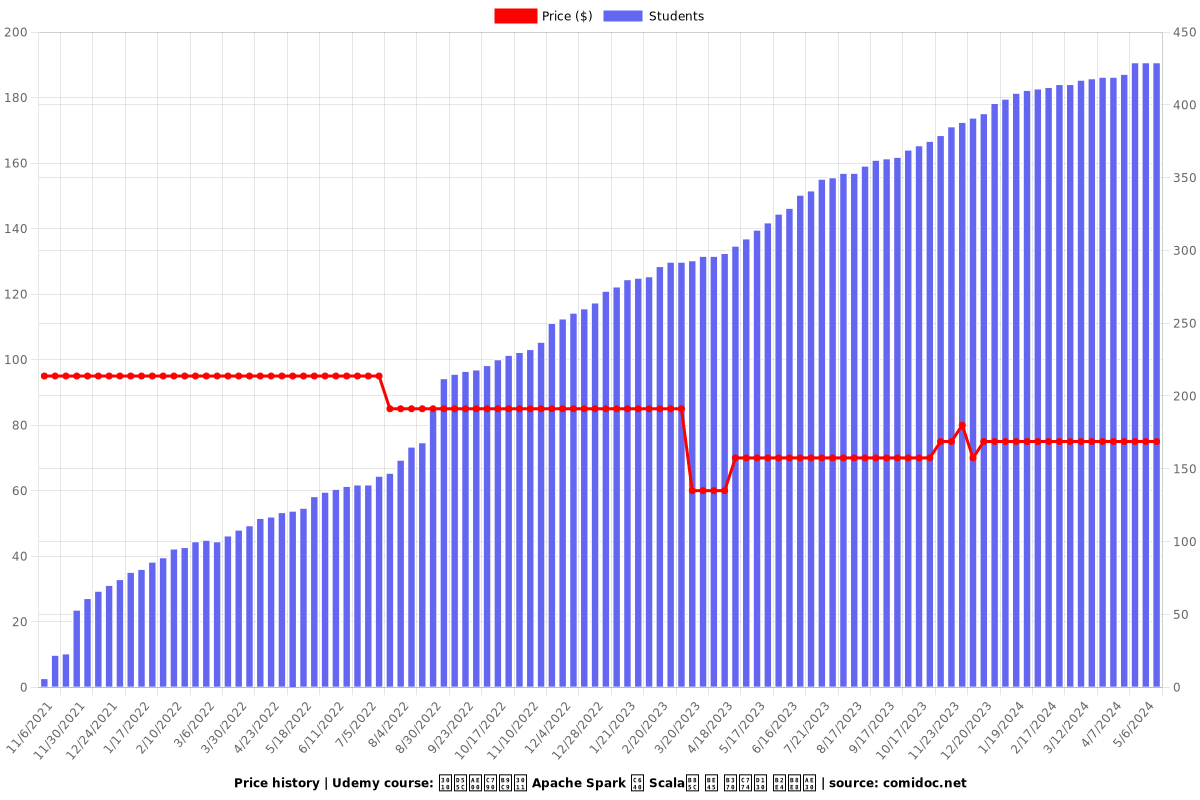
Rating
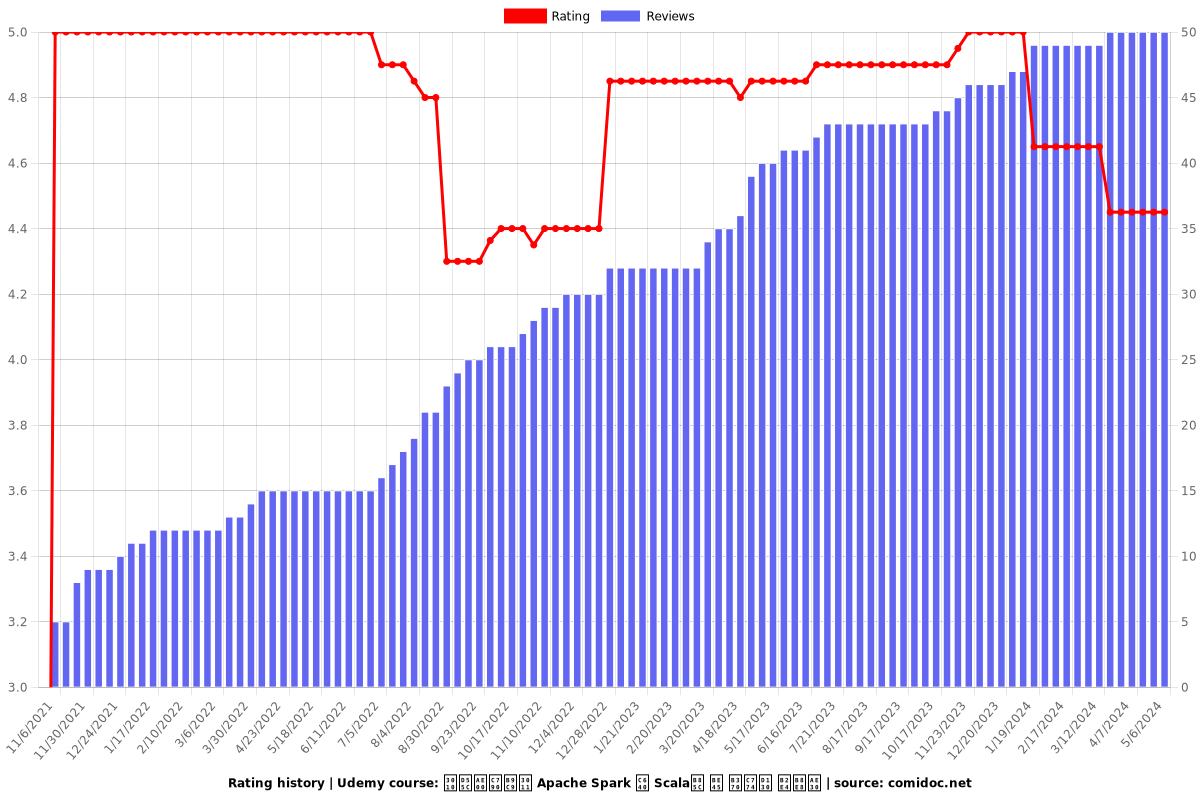
Enrollment distribution