【한글자막】 Hadoop : 여러 실습으로 빅 데이터 길들이기!
【전세계 81만 수강 강사!】 MapReduce, HDFS, Spark, Flink, Hive, HBase, MongoDB, Cassandra, Kafka 등이 포함된 Hadoop 자습서! 25개 이상 기술 학습하기

What you will learn
Hadoop 및 관련 기술을 사용하여 "빅데이터"를 관리하는 분산 시스템 설계
HDFS 및 MapReduce를 사용하여 대규모 데이터 저장 및 분석
Pig 및 Spark를 사용하여 스크립트를 만들어 Hadoop 클러스터에서 보다 복잡한 방식으로 데이터를 처리
Hive 및 MySQL을 사용하여 관계형 데이터를 분석
HBase, Cassandra 및 MongoDB를 사용하여 비관계형 데이터를 분석
Drill, Phoenix 및 Presto를 사용하여 대화식으로 데이터 쿼리
애플리케이션에 적합한 데이터 스토리지 기술 선택
YARN, Tez, Mesos, Zookeeper, Zeppelin, Hue 및 Oozie에서 Hadoop 클러스터를 관리하는 방법 이해
Kafka, Sqoop 및 Flume을 사용하여 Hadoop 클러스터에 데이터 게시
Spark Streaming, Flink 및 Storm을 사용하여 스트리밍 데이터 사용
Why take this course?
아마존, IMDb에서 근무한 엔지니어들과 시니어 매니저들이 가르쳐주는 실전 강의!
Hadoop 튜토리얼을 통한 전반적인 이해와 실제 비즈니스 문제까지!
Hadoop을 넘어 모든 종류의 분산 시스템에 대한 내용을 담은 강의!
25가지의 기술을 포함, 다양한 실습과 연습문제 포함!
Hadoop 빅데이터 길들이기! 강의를 선택해야 하는 이유
Hadoop을 이해하는 것은 데이터 양이 많은 회사에서 일하는 모든 사람에게 매우 유용한 기술입니다.
Amazon, Ebay, Facebook, Google, LinkedIn, IBM, Spotify, Twitter, 그리고 Yahoo 등과 같은 여러분들이 일하고 싶은 대부분의 대기업들은 어떠한 방식으로든 Hadoop을 사용합니다. Hadoop이 필요한 것은 기술 회사뿐만이 아닙니다. New York Times에서도 이미지 처리에 Hadoop을 사용합니다.
이 강의는 포괄적입니다. 25가지 이상의 다양한 기술을 14시간의 비디오 강의 에 담았습니다 실습과 연습 문제로 가득 차 있으므로 Hadoop 사용에 대한 실제 경험을 얻을 수 있습니다. 단순히 이론만 있는 것이 아닙니다.
이 강의에서 모든 수준의 사람들을 위한 다양한 활동을 찾을 수 있습니다. 유행어를 배우고자 하는 프로젝트 관리자라면 이 강의에는 프로그래밍 지식이 필요하지 않은 많은 활동에 대한 웹 UI가 있습니다. 명령 줄에 익숙하다면 사용 방법도 보여드리겠습니다. 그리고 여러분이 프로그래머라면 Scala, Pig Latin, 그리고 Python을 사용하여 Hadoop 시스템에서 실제 스크립트를 작성하도록 도전하겠습니다.
여러분은 Hadoop 및 관련 분산 시스템에 대한 실제적이고 깊은 이해를 바탕으로 이 강의를 마치고 Hadoop을 실제 문제에 적용할 수 있습니다. 그리고 마지막에는 귀중하고 멋진 수료증이 여러분을 기다리고 있습니다!
이 강의의 초점은 Hadoop 관리가 아니라 애플리케이션 개발에 있습니다. 이 강의에서 몇 가지 관리 기술을 배우게 됩니다.
Hadoop 빅데이터 길들이기! 강의에서는 이런 내용을 학습합니다.
Hortonworks (현재 Cloudera의 일부) 및 Ambari UI 를 이용하여 데스크탑에 바로 실제 Hadoop을 설치하고 작업하는 법.
HDFS 그리고 맵리듀스를 이용해 클러스터에서 빅 데이터 관리
Pig 와 Spark를 이용해 Hadoop에서 데이터를 분석하는 프로그램 작성
Sqoop, Hive, MySQL, HBase, Cassandra, MongoDB, Drill, Phoenix 및 Presto를 사용하여 데이터 저장 및 쿼리
하둡 에코시스템을 사용하여 실제 시스템 설계
다음의 기능들을 사용하는 클러스터 관리 방법 알아보기: YARN, Mesos, Zookeeper, Oozie, Zeppelin, 그리고 Hue
실시간 스트리밍 데이터 처리 Kafka, Flume, Spark Streaming, Flink, 그리고 Storm
전 세계 81만 수강 강사 Frank Kane의 한마디
Hadoop 의 세계, 그리고 "빅 데이터"는 자칫 너무 어려워 보일 수도 있습니다 - Hadoop 에코시스템을 구성하는 수수께끼같은 이름을 가진 수백 가지의 다양한 기술이 모여 형성 되어 있기 때문이지요. 하지만 여러분들은 Hadoop 튜토리얼을 통해 이러한 시스템이 무엇이고 어떻게 서로 잘 맞는지 이해할 수 있을 뿐만 아니라 실제 비즈니스 문제를 해결하기 위해 이를 사용하는 방법도 직접 배울 수 있습니다!
이 완벽한 종합 과정에서 가장 인기 있는 빅 데이터 기술을 배우고 마스터하십시오. 이 강의는 아마존 그리고 IMDb에서 근무한 엔지니어들과 시니어 매니저들이 가르칩니다. 우리는 Hadoop 자체를 넘어 통합할 수 있는 모든 종류의 분산 시스템에 대해 자세히 알아볼 것입니다.
"빅 데이터"를 다루는 방법을 아는 것은 오늘날 TOP 테크 고용주에게 매우 귀중한 기술입니다. 뒤쳐지지 마세요 - 지금 강의에 등록하고 이 강의를 즐겨보시기 바랍니다!
강의를 들으시고 강의와 관련하여 궁금하신 점은 무엇이든 Q&A에 남기실 수 있지만, 꼭 영어로 남겨주세요. 그래야 답변을 드릴 수 있습니다. :)
-Frank
P.S. 제 강의에 대한 수강생들의 리뷰를 소개해 드립니다:
"Ultimate Hands-On Hadoop...은 저에게 중요한 발견이었습니다. 인터뷰를 할 수 있을 때까지 많은 문헌과 컨퍼런스로 강의를 보완했습니다. 저는 당신의 강의를 시작한 지 약 1년 만에 빅 데이터 엔지니어로 취업했다고 자랑스럽게 말할 수 있습니다. 당신이 생성한 모든 훌륭한 콘텐츠와 명확한 설명에 감사드립니다. " - 알도 세라노
"솔직히 이 강의가 없었다면 지금의 저는 없었을 것입니다. Frank는 프로세스의 모든 단계를 도와줌으로써 복잡한 것을 간단하게 만듭니다. 특히 Spark 환경을 적극 권장하고 시간을 할애할 가치가 있습니다. 이 강의를 통해 환경과 그 기능에 대해 훨씬 더 잘 이해할 수 있었습니다. Frank는 프로세스의 모든 단계를 도와줌으로써 복잡한 것을 간단하게 만듭니다. 특히 Spark 환경을 적극 권장하고 시간을 할애할 가치가 있습니다." - Tyler Buck
Screenshots




Charts
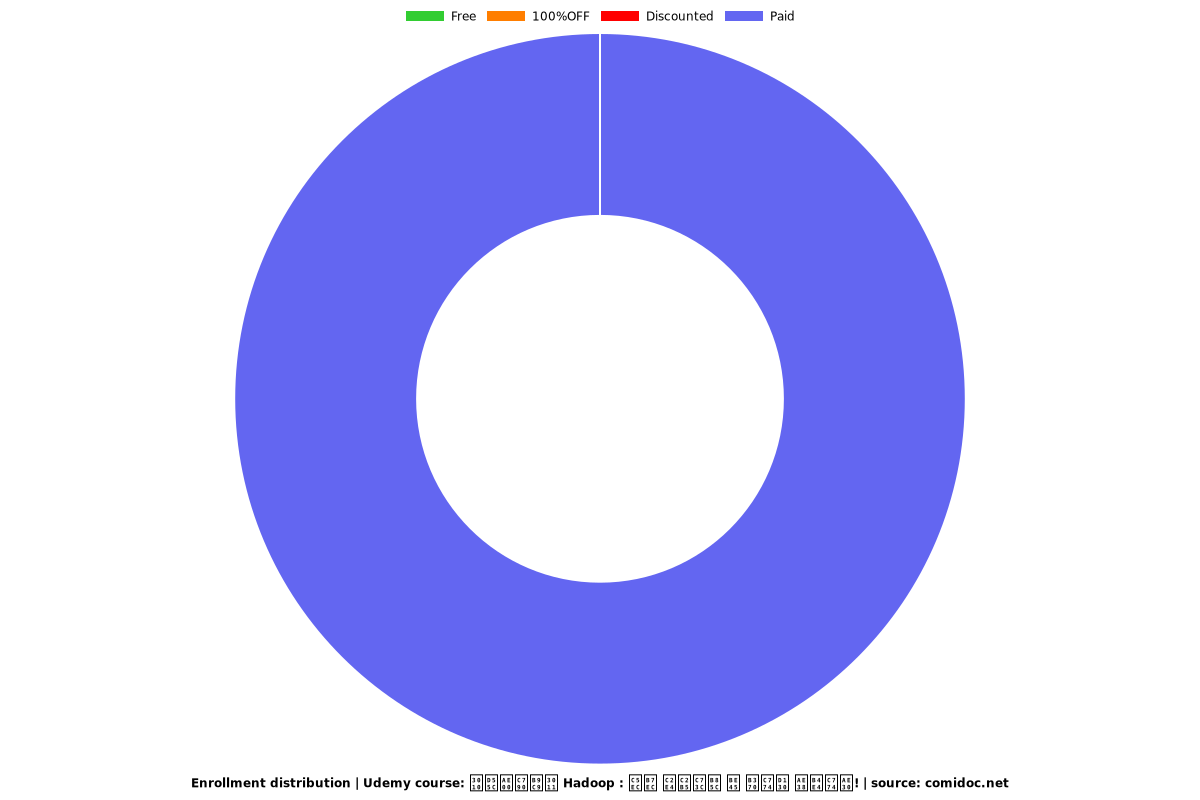
Price
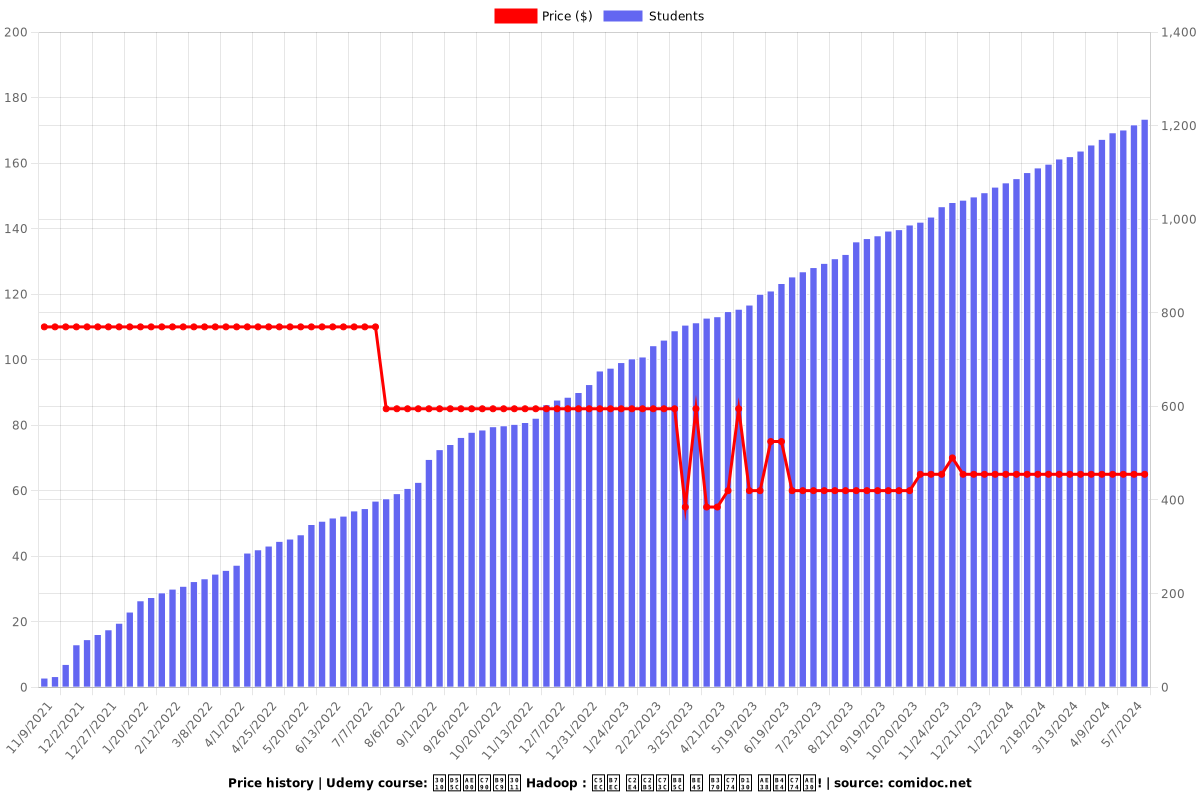
Rating
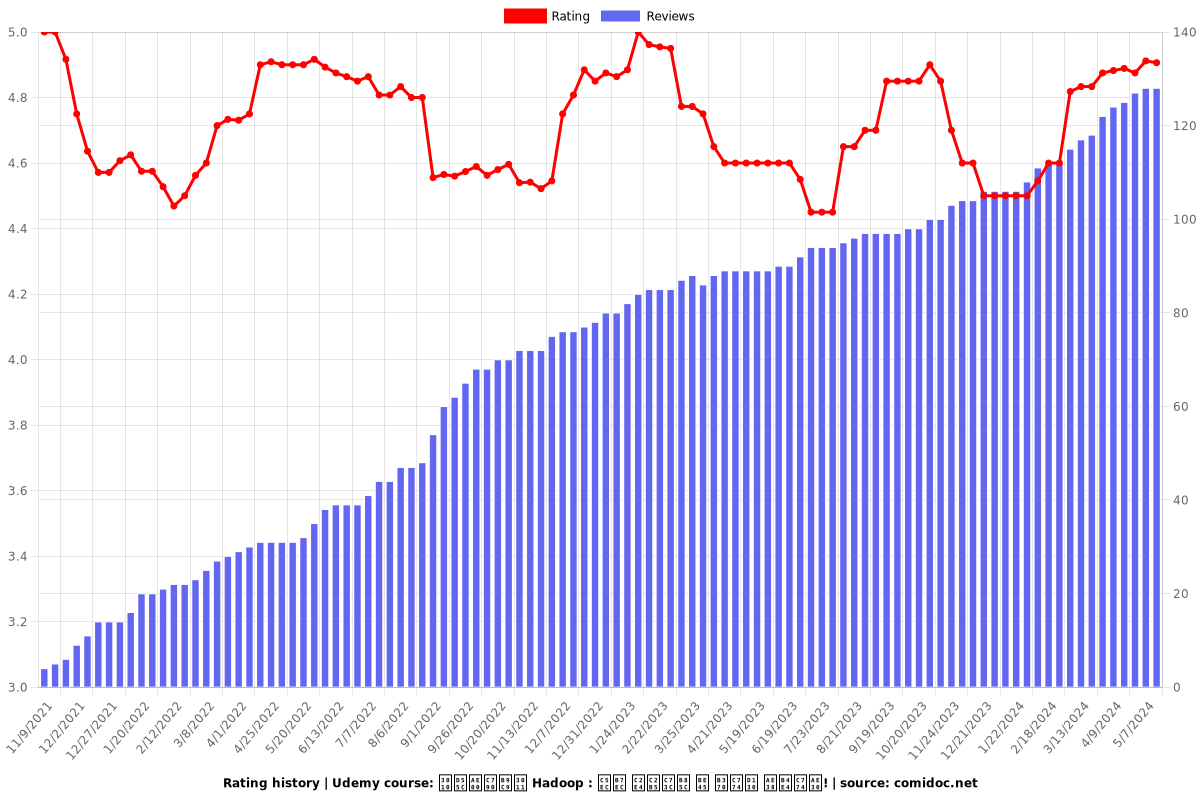
Enrollment distribution