Apprentissage par renforcement avec Python - Partie 1
Intelligence artificielle (IA), Machine Learning, Reinforcement Learning (RL)-théorie et applications en langage Python

What you will learn
Comprendre le fonctionnement de l'apprentissage par renforcement et les concepts généraux associés
Comprendre les différentes approches permettant de résoudre les problèmes d'apprentissage par renforcement et trouver le plus adapter
Comprendre en profondeur le fonctionnement des différents algorithmes utilisés
Comment coder l'ensemble des algorithmes proposés en langage Python sur de nombreux exemples
Why take this course?
L’intelligence artificielle s’invite dans tous les secteurs. Toutefois, contrairement à ce que l’on peut penser, l’IA n’est pas une technologie unique.
Il existe de nombreuses branches et sous-catégories telles que le Machine Learning et le Deep Learning. Dans cette formation, je vous propose de vous initier à l’apprentissage par renforcement (Reinforcement Learning). Vous utiliserez le langage de programmation Python et des librairies spécialisées dans le traitement des données comme par exemple Numpy.
À l’heure actuelle, l’apprentissage par renforcement se révèle comme la façon la plus efficace de faire appel à la créativité des machines. Contrairement à un humain, une intelligence artificielle peut effectuer des milliers de tentatives en simultané. Il suffit pour ce faire de lancer le même algorithme en parallèle sur une puissante infrastructure informatique.
J’ai pris soin dans cette formation de vous fournir des explications claires et de nombreux exemples vous permettront de bien comprendre comment sont construits les algorithmes et comment les mettre en œuvre en Python. Cette formation d’initiation à l’apprentissage par renforcement est organisée de la manière suivante :
Introduction à la problématique de l’apprentissage par renforcement
Approche des équations de Bellman
Application sur un projet réel
Méthodes d'optimisation basées sur la programmation dynamique
Méthodes de Monte-Carlo
Apprentissage par différences temporelles (TD Methods) - Sarsa et Q-learning
Méthodes par différences temporelles n-Step (n-step TD Methods)
Les activités en Python sont clairement expliquées. D'une durée totale de 9h, ce cours vous permettra de comprendre et de mettre en application les algorithmes d’apprentissage par renforcement.
=== Prérequis ===
Des connaissances en Python sont un plus. Pour les parties davantage théoriques qui expliquent comment sont construits les algorithmes, des connaissances en Mathématiques (en particulier dans le domaine des probabilités) sont également un plus.
Les expériences menées dans ce cours sont réalisées à l'aide des carnets jupyter. Il vous faut donc également un accès à un environnement de type jupyterlab, comme par exemple avec Google Colab (gratuit avec un compte gmail). Toutes les ressources sont fournies avec le cours.
=== Thèmes étudiés dans la formation ===
#1. Introduction à la problématique de l’apprentissage par renforcement
L’apprentissage par renforcement ou Reinforcement Learning est une méthode de Machine Learning. Elle consiste à entraîner des modèles d’intelligence artificielle d’une manière bien spécifique.
L’agent IA doit apprendre à atteindre un objectif au sein d’un environnement incertain et potentiellement complexe. Pour y parvenir, l’ordinateur essaye toutes les façons possibles et apprend de ses erreurs. À chaque tentative, l’IA reçoit une récompense ou une punition en fonction des actions effectuées. Elle est programmée pour maximiser sa récompense, et tentera donc de trouver la méthode le lui permettant. Le programmeur se charge de mettre en place les conditions de récompenses. Il se charge donc de fixer les "règles du jeu".
En revanche, aucune instruction, aucun indice n’est donné à l’agent IA pour lui suggérer comment accomplir la tâche demandée. C’est à lui de découvrir comment maximiser sa récompense, en commençant par des tentatives totalement aléatoires pour terminer par des tactiques extrêmement sophistiquées.
Un des nombreux concepts important pour mener à bien ce travail est de modéliser correctement l’environnement dans lequel l’agent évolue. Cela se fait à l’aide des processus de décision Markovien (MDP – Markov Decision Process). Une grande partie de ce module est dédié à l’étude de ces processus.
#2. Approche des équations de Bellman
La plupart des algorithmes d’apprentissage par renforcement sont basés sur l’estimation de fonction de valeur (valeur d’état ou valeur de couple état-action). Ces fonctions estiment de combien il est bon d’être dans un état de l’environnement ou de combien il est bon d’effectuer une action dans un état spécifique. La notion « de combien » est définie par les récompenses futures attendues par l’agent qui explore l’environnement, autrement dit par le retour attendu par l’agent qui utilise une stratégie spécifique d’exploration.
Les équations de Bellman permettent de calculer ces fonctions de valeurs. Elles sont à la base des algorithmes qui en découlent et qui chercheront à trouver leurs valeurs optimales dans le but de construire des stratégies optimales.
#3. Application sur un projet réel
Les concepts introduits dans les deux premières parties sont extrêmement importants pour la suite. Pour mieux les comprendre et être à l’aise avec les problématiques qu’ils posent, dans cette partie vous les mettrez en application dans un projet réel.
Ce projet à pour but de guider une personne aveugle dans un magasin pour le diriger vers un article qu’il souhaite acheter. Ici, l’objectif de l’algorithme d’apprentissage par renforcement sera de trouver une trajectoire optimale. Vous verrez comment les équations de Bellman peuvent aider à résoudre ce problème.
#4. Méthodes d'optimisation basées sur la programmation dynamique
La programmation dynamique est une méthode qui permet d’écrire des algorithmes de manière plus optimisée que les méthodes séquentielles. Elle permet de résoudre les équations d’optimalité de Bellman nécessaires pour trouver les solutions aux problèmes d’optimisation des stratégies.
Plusieurs exemples sont vus au cours de ce module pour se familiariser avec la programmation dynamique, avant d’appliquer cette méthode à la résolution des équations de Bellman.
#5. Méthodes de Monte-Carlo
Les méthodes de Monte-Carlo apporte davantage de flexibilité et donnent des solutions à des problèmes qui ne peuvent pas être résolus avec les méthodes de programmation dynamique.
Tout au long de ce module, nous nous intéresserons à appliquer ces méthodes afin de trouver des stratégies de jeu optimales au Blackjack, jeu de carte qui par essence est très aléatoire et donc impossible à prédire.
#6. Apprentissage par différences temporelles (TD Methods) - Sarsa et Q-learning
Dans certaines situations, les méthodes vues précédemment sont incapable de fournir des solutions à nos problèmes. C’est le cas par exemple lorsque l’agent évolue dans un environnement et qu’il peut éventuellement ne jamais terminer une partie de jeu… voire quand les parties ne se terminent jamais.
Plusieurs algorithmes très connus sont issus des méthodes par différences temporelles, comme les méthodes Sarsa et Q-learning.
Q-learning et Sarsa se ressemblent beaucoup mais Sarsa est une méthode dite on-policy alors que Q-learning est une méthode dite Off-policy. Cela signifie qu'il permet de comparer les récompenses probables sans avoir de connaissance initiale de l’environnement. En d'autres termes, bien que le système soit modélisé par un processus de décision markovien, l'agent qui apprend ne le connaît pas et l'algorithme du Q-learning ne l'utilise pas.
Nous verrons que cette petite différence entre Sarsa et Q-learning rend Q-learning un peu plus efficace, mais Sarsa plus sûre.
#7. Méthodes par différences temporelles n-Step (n-step TD Methods)
Les méthodes de Monte-Carlo et par différences temporelles sont en quelque sorte deux méthodes diamétralement opposées, qui apportent chacune des avantages bien spécifiques mais également des incovénients…
Les méthodes multi-pas (de type n-step) ont pour but de mettre en commun ces deux manières opposées de résoudre les problèmes afin de les unifier.
Screenshots




Reviews
Charts
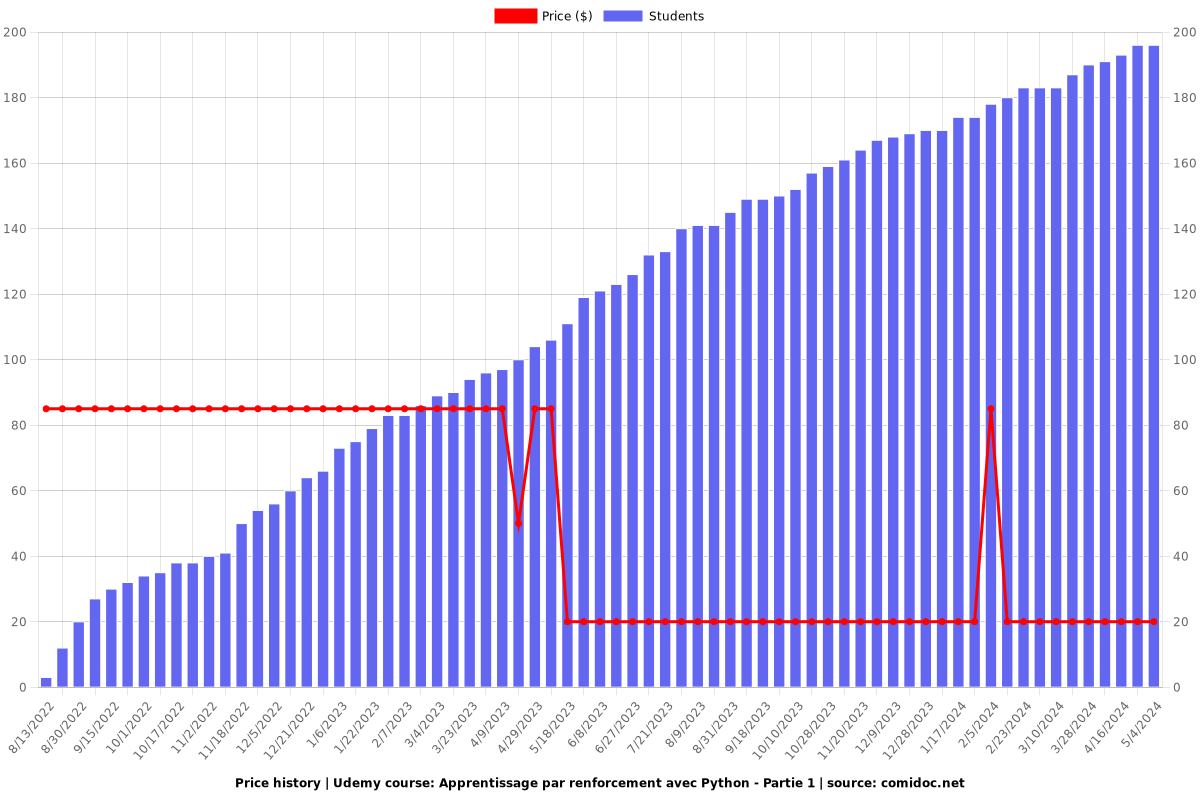
Price
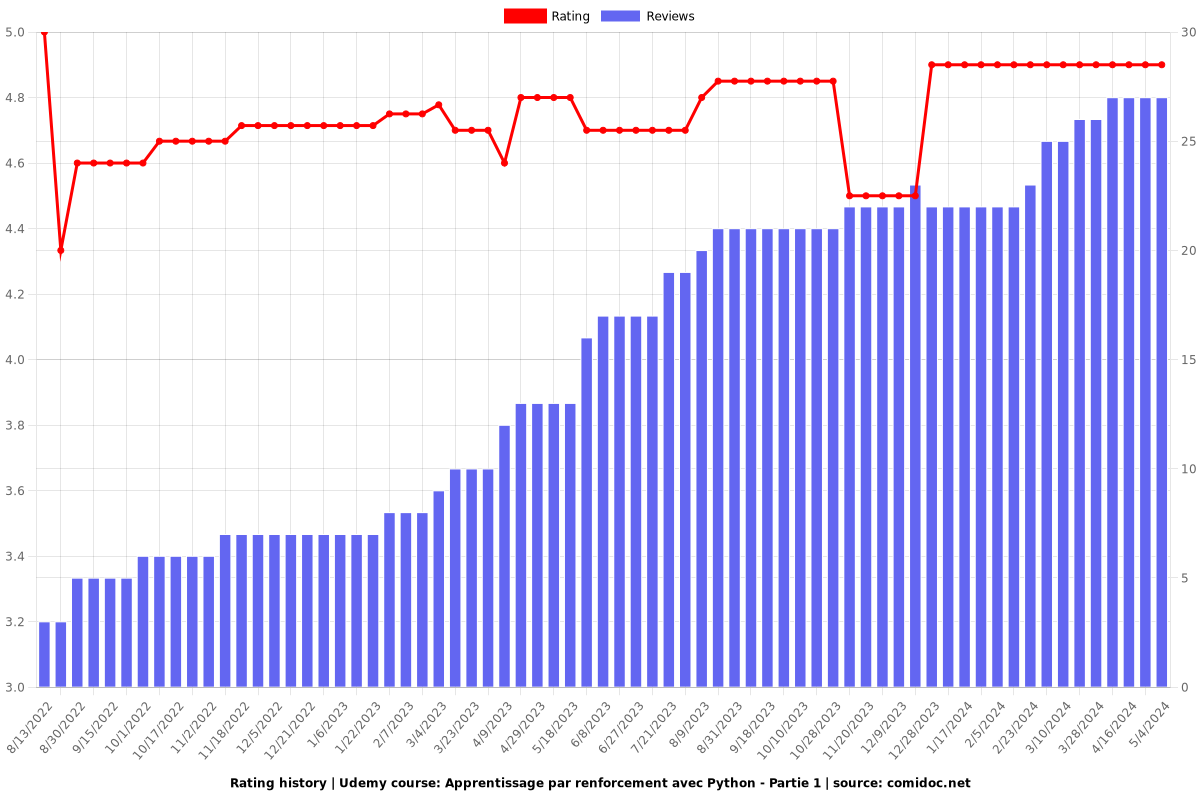
Rating
Enrollment distribution